AI图片著作权第一案掀波澜,新技术将改写著作权法?

原题 | AI图片著作权第一案错判?探索人机创作的版权边界
作者 | 陈 焕 北京市隆安(广州)律师事务所律师
叶俊希 北京市隆安(广州)律师事务所合伙人
编辑 | 布鲁斯

北互9月份的笃定
当北京互联网法院被公开的“AI生成图片著作权侵权第一案判决书”一天内阅读量就达到10万+的时候,不知道北互是否还记得,那份23年9月在此发布的、在2020年被定为“典型案例”的判决书……

在那个典型案例中,法院认为:
作品应由自然人创作完成,在相关内容的生成过程中,软件研发者(所有者)和使用者的行为并非创作行为,相关内容并未传递二者的独创性表达。因此,二者均不应成为计算机软件智能生成内容的作者,该内容亦不能构成作品。软件研发者(所有者)和使用者均不能以作者身份进行署名,但是,从保护公众知情权、维护社会诚实信用和有利于文化传播的角度出发,应添加相应计算机软件的标识,标明相关内容系软件智能生成[1]。
但两个多月后的今天,在这份“AI生成图片著作权侵权第一案判决书”中,北互却做出了截然相反的认定,认为Stable Diffusion模型涉案图片符合作品的定义,属于作品,而原告是涉案图片的作者。
尽管我国并非判例法国家,但在如此短的时间内,对同类案件做出截然相反的判断,仍旧让人感到非常意外。难道以Stable Diffusion模型为代表的模型,已经不是典型案例里的“计算机软件智能”了吗?还是说,人工智能生成物的可著作权性之争,已经迎来了“终极反转”?
我们讲尝试以无技术背景也能够看懂的陈述方式,为读者朋友梳理案件的基本事实和法院的逻辑;同时,对于争议不大的内容,我们将不做赘述,以免影响阅读体验。如果读者想要了解更多技术方面的讨论,可以阅读我们团队的李律师的另一篇文章《谁拥有算力,谁垄断国内AI著作权的未来?》[2]。

原告是如何使用Stable Diffusion生图的?
原告使用Stable Diffusion模型做图的流程可以简要归纳如下:
1.在网络上下载Stable Diffusion整合包、模型包等必要的程序。(这是使用Stable Diffusion模型时必要的软件安装环节);
2.输入正向提示词(这个环节的目的是,告诉Stable Diffusion模型,我需要什么);
3.输入反向提示词(这个环节的目的是,告诉Stable Diffusion模型,我不要什么)。根据原告称述,反向提示词绝大多数来源于网络,原告仅做了细微调整;
4.修改参数、固定随机数种子(这个环节可以简化理解为,进一步告诉Stable Diffusion模型,我选中了某个图片的大致类型了,你在这个图片的基础上,帮我微调细节即可);
5.继续调整参数、随机数种子、提示词(通过修改前述设置,进一步微调图片);
6.最终得到了涉案图片,如下图:
 (图片于该案原告小红书账号“董二千”上发表,截自公众号“知产库”的文章《AI生成图片著作权侵权第一案判决书》[3])
(图片于该案原告小红书账号“董二千”上发表,截自公众号“知产库”的文章《AI生成图片著作权侵权第一案判决书》[3])
原告认为,“从模型的选择及选取、提示词及反向提示词的输入、生成参数的设置,均可以体现出原告的取舍、选择、安排和设计,凝结了原告的智力劳动,其显然具有独创性……被告未经其许可使用涉案图片且截去了其在小红书平合的署名水印,侵害原告对涉案图片享有的署名权和信息网络传播权。”

法院为什么认为,涉案图片是作品?
结合原告的举证,法院提出了自己的观点,认为考虑涉案图片是否构成作品,需要考虑以下几个要件:
1.是否属于文学、艺术和科学领域内;
2.是否具有独创性;
3.是否具有一定的表现形式;
4.是否属于智力成果。
法院认为,涉案图片完全符合这四个要件,因此认定该图片是作品。但法院并未花费太多的笔墨在要件1和要件3。我们把注意力放在“独创性”和“智力成果”的讨论上来。
1. 法院看“智力成果”要件
(1)Stable Diffusion模型能力的来源,是通过训练,获得了类似人类的能力和技能;
(2)Stable Diffusion模型生成图片时,不是通过搜索引擎调用已有的现成图片,也不是将软件设计者预设的各种要素进行排列组合;而是根据人类输入的文宇描述生成相应图片,代替人类画出线条、涂上颜色,将人类的创意、构思进行有形呈现;
(3)从原告构思涉案图片起,到最终选定涉案图片止,提供了提示词和参数,这整个过程来看,原告进行了一定的智力投入。
据此,法院得出了“涉案图片具备了‘智力成果’要件”的结论。
2. 法院看“独创性”要件
(1)“机械性智力成果”应当被排除在外。比如按照一定的顺序、公式或结构完成的作品,不同的人会得到相同的结果,因表达具有唯一性,因此不具有独创性。
(2)而人们利用Stable Diffusion类模型生成图片时,所提出的需求与他人有差异,原告通过提示词、参数等方式,对图片的人物、构图等呈现方式进行了设计,又通过进一步的提示词和参数修改,最终得到了涉案图片,体现了“原告的审美选择和个性判断”
(3)又因为利用该模型进行创作的其他人,可以自行输入新的提示词、设置新的参数,生成不同的内容。
据此,法院得出了“涉案图片具备了‘独创性’要件”的结论。
3. 法院对“新一代生成式人工智能技术“的看法
(1)创作方式变化:技术的发展过程,就是把人的工作逐渐外包给机器的过程。智能手机的发展,让“再现客观物体形象”变得容易,只要运用相机拍摄出具有“独创性”的“智力成果”,就应当构成摄影作品。
(2)不影响适用著作权鼓励创作。使用人工智能创作,本质上仍然是人利用工具进行创作,即整个创作过程中进行智力投入的是人而非人工智能模型。对这种形态下创作的保护,有利于鼓励更多的人用最新的工具去创作,有利于作品的创作和人工智能技术的发展。

为什么我们认为法院的观点不妥?
1. AI像一只会画画的大大猩猩伊万,它画的画不是“作品”,它的主人也不是“作者”
当我们聊到作者创作中使用了拥有一定智能的“工具”时,我们常常会聊起美国的“猴子自拍”的案例。在这个案例中,摄影师Slater放任猴子按下快门,拍摄了大量照片,并选出来最有趣的两张照片,发到了网站上。

(Slater持有的“猴子自拍”图)
但在随后的版权保护官司中,Slater输掉了官司。因为《美国版权法》认为,动物不可以成为作者,作者必须是人。
假如我们将北互案件中的Stable Diffusion这种具有一定智能程度的计算机软件,类比成“猴子自拍”图中的猴子,从而说明涉案图片也不构成作品,是否恰当呢?
在本案中,恐怕不足以成为足够有力的说理。
因为本案中,法院认为人工智能的本质是工具,否认人工智能(猴子)成为作者的可能性。但是,使用工具的人,由于控制、使用人工智能工具,并且通过提供、调整提示词、参数和固定随机数种子的方式,获得了涉案图片,这个过程中,体现了人的独创性取舍和选择。而“猴子自拍”案中,Slater只是放任猴子按下快门,并且在猴子自拍、图片制作完成后,被动地选择猴子随机拍摄的照片,在图片制作的过程中,Slater并没有提供足够的独创性安排和取舍。
因此,“猴子自拍”案的认定逻辑,并不足以辩驳法院“工具论”和“独创性取舍和选择论”的观点。
但有一个根据真实事件改编的故事,可以帮我们理清法院说理逻辑的谬误。下面是电影《独一无二的伊万》[4]的画面截图:

(画面一:一次巧合之下,小女孩发现大猩猩伊万会作画,向它提供了专业的颜料)
(画面二:小女孩进一步提供了自己的作品,笔者理解到这幅作品的主题,大约为“我和妈妈去亲近大自然”)

(图三:大猩猩伊万理解了图画的意思,并联想起自己的童年的大自然生活和用泥巴作画的经历)

(图四:大猩猩伊万开始使用颜料进行作画,最终作出了令人震撼的画幅,完全符合一般认知下的“作品”的外观)
尽管这个故事可能有一定的虚构和艺术成分,因为大猩猩伊万即便具有较高的智能程度,可能也难以真的画出如此令人惊讶的“作品”,但这个故事却比“猴子自拍”,更加贴合我们所讨论的人工智能作图的场景。
首先,大猩猩伊万的童年有亲近大自然的经历和用泥巴画图的经历——就像人工智能通过训练学会了某种“技能”;
其次,小女孩给大猩猩伊万提供了学习样本和创作素材——就像人通过提示词和参数,向人工智能提出了画图的要求;
最后,大猩猩伊万理解了小女孩的样图含义,并基于“童年的经验”进行创作——就像人工智能为用户生成了图片。
在这个故事中,小女孩只是提供了一份样本和原材料,向大猩猩伊万做出作画的指引,大猩猩伊万就“自动”的创作了一副令人震撼的画面——这与使用人工智能作画的用户的行为,本质上有何区别?
更何况从小女孩提供的画作样本来看,所传达的信息(或提示词),甚至比人工智能从用户手里得到的提示词更为丰富、具体,更具“独创性取舍和选择”。那么,难道我们要据此得出“小女孩以大猩猩伊万为工具,通过一系列的独创性取舍和编排,通过大猩猩伊万创作了一副著作权法意义上的作品,小女孩是这副作品的作者”这样的结论吗?
如果这样的结论让你感到不适,那么,仅仅是在电脑前提供了一点提示词和参数的人工智能用户,又怎么会因为这些所谓的“独创性取舍和选择”,就可以得到人工智能生成物的著作权呢?
由此看来,法院基于“从原告构思涉案图片起,到最终选定涉案图片止,提供了提示词和参数,这整个过程来看,原告进行了一定的智力投入”的论述,得出“涉案图片具备了智力成果要件”的结论,恐怕并不恰当。
2.AI虽然不是在“搜索”,却是实打实地在“组合”
法院对于“机械性智力成果”不具有独创性持肯定态度,但认为Stable Diffusion类模型生成图片的过程并非“按照一定的顺序、公式或结构完成的作品”,表达不具有唯一性,从而认为Stable Diffusion类模型的生成物并非“机械性智力成果”。
那么换句话说,只要我们能够证明:“Stable Diffusion类模型生成图片的过程,确实是按照一定的顺序、公式或结构完成的作品”,就可以让法院的推论失去事实依据。
我们尝试用极简的语言,来描述Stable Diffusion类模型从训练,到生图,再到“复现”的过程,就可以看出法院观点的谬误。
(1)训练阶段
Stable Diffusion类模型,通过“正向扩散”、“反面扩散”、“噪声预测器”等技术方案,让人工智能学会了一只“猫”应有的特征和生成“猫”的方法。(这个过程中的变分自编码器、潜空间、分词器等概念较为复杂,读者可以略过。有兴趣的,可以查阅《深入浅出讲解Stable Diffusion原理,新手也能看明白》[5]进一步了解。)

(正面扩散)
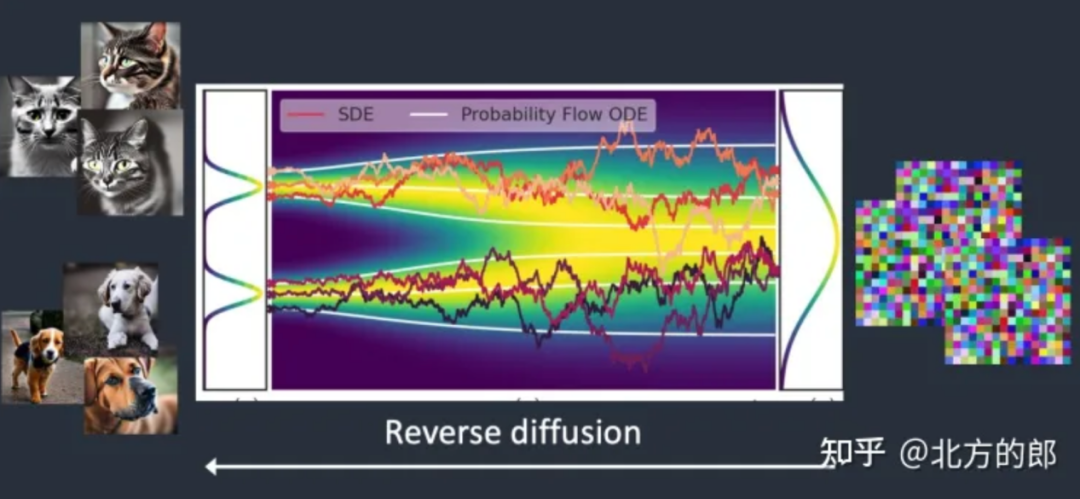
(反面扩散)
(2)生成阶段
Stable Diffusion类模型,从一个随机噪声状态(即上图中的“马赛克状态”)开始,接收用户的提示词和参数,利用训练阶段学习到的特征,从随机噪声状态开始向后扩散。在这个过程中,用户可以通过继续提供提示词、修改参数、更改随机数种子的方式,由模型逐步改进图像,使其更加清晰,更贴近用户的文本描述。
但是需要注意的是,如果模型在训练过程中没有接触到某些特定的特征,它在理解和生成这些特征方面通常会受到限制。如果模型没有学过什么是“猫”,就无法画出“猫”。但是,模型可以通过组合和变形的方式,利用它已经学习到的特征,来生成新颖的图像。也就是说,如果模型已经学过很多只猫,那么它可以通过组合各种猫的特征,来创造出史无前例的猫的图片。
这样看来,法院说的:“不是通过搜索引擎调用已有的现成图片,也不是将软件设计者预设的各种要素进行排列组合”,这句话只对了一半,Stable Diffusion生图的过程确实不是检索,但却是实打实地在对预设的特征进行排列组合。
(3)在本案中法院提及的所谓的“复现”阶段
如果使用相同的模型版本、相同的提示词、相同的参数设置,以及相同的随机种子,理论上应该能够复现出完全一样的图片。图像生成模型在给定相同的输入和初始状态(即随机种子)下,其内部的计算是确定的。也就是说,生成阶段所完成的各种组合和变形,会通过前述相同的设置固定下来。因此,当所有这些条件保持不变时,模型将重复相同的计算过程,从而生成相同的输出。
更重要的是,模型可以“通过使用相同的模型版本、相同的提示词、相同的参数设置,以及相同的随机种子进行复现”的事实,已经被法院进行了确认。在本案中,法院认定了原告提交的“涉案图片复现视频”证据的真实性,原告通过固定前述设置的方式,得到了与原图完全一致的图片……
这难道不正是StableDiffusion模型“按照一定的顺序、公式或结构完成的作品”最有力的例证吗?
既然StableDiffusion模型确实可以“按照一定的顺序、公式或结构完成作品”,那不就是法院认为不应该具有独创性的“机械性智力成果”吗?
因此,法院赖以讨论“独创性”的事实基础是不存在的,其得出的具有“独创性”的结论,自然也是错误的。
3. 【交警拍违章】再容易使用的工具,也要区分“思维”与“表达”的界限
尽管我们认同法院“技术的发展过程,就是把人的工作逐渐外包给机器的过程”的说法,却无法认可法院在说理时,将“人的工作”简单地等同于著作权法意义上的“创作”。
无论技术发展到何种程度,机器实现了何种智能,只要著作权法的立法目的仍旧为“鼓励创作”,就仍始终应当将人的智慧贡献、人类思想的表达,作为评价作品“独创性”不可或缺的标准。
智能手机的飞速发展,让再现客观物体形象更加容易,但法院也认可需要运用这些相机拍摄出具有独创性的智力成果,才能被认定为作品。也正因如此,道路交通高清摄像机自动抓拍的实时路况,无论拍出来的照片多么具有美感,都因为没有人的独创性智慧贡献而不具有独创性。

(违停抓拍,图源网络)
随着人工智能技术的发展,人工智能已经演化出令人惊诧的能力,能够轻而易举地生成与人类创作外观极为接近的“作品”。但在生成内容的时候,人类提供的几个提示词、几个参数,本质上并非参与到生成物的“表达”中去,而仅仅是根据既往的经验,向人工智能提供了一些“人类的想法”。
也许在人工智能“眼中”,人类只是絮絮叨叨的甲方,不断地提出天马行空的想法和需求。有时候提的需求没办法满足,就随意找个相近的特征糊弄一下,做得不好的时候,还会被这些碳基生物讽刺“胡说八道”。但你要说这是人类的“表达”,恐怕连人工智能都不服气。
按照法院的观点,用户除了提供提示词、参数、安装包和随机数种子之外,几乎什么都不用干,让AI生成的图片就可以受到著作权法保护;在此情况下,任何人只要使用同一个套设置,也能够生成几乎完全相同的一副画作,但却会因此涉嫌著作权侵权。
从这个角度上看,这是否意味着,法院实质上也保护了这套“提示词、参数、安装包和随机数种子”的“固定搭配”,意味着这套“固定搭配”可以被某个用户垄断?如果按照这样的保护逻辑,那么法院保护的到底是AI生成的画作,还是这套“固定搭配”?“固定搭配”和“AI生成的画作”二者的“思维”和“表达”的界限又在哪里呢?
但这套固定搭配,明明只是一些使用AI工具的经验和思维罢了。
当然,我们并不是说,使用AI工具必然不能产生符合著作权法意义的作品。用户完全可以在AI生成的基础上,使用绘图工具增加自己的表达;也可以参考AI生成物的提供的灵感,另行创作更多精彩的画作。究其根本,还是要以“人的独创性表达”为标准,对“是否构成著作权法意义上的作品”这一问题进行评价。
不仅如此,对AI生成物是否具有可版权性的讨论,也囿于当前的技术发展水平。如果人工智能进一步发展,在创作范式上增大了人的独创性贡献,让人类可以创作出更伟大的作品;又或者人工智能进一步获得突破,演化出真正意义上的“意识”,凭其觉醒的意识自由创作……那么,届时著作权法理论当作何种发展,将是未来学界和实务界继续争论不休的话题,也且让我们保持“发展的眼光”来看待这些问题吧。

美、日的“他山之石”
1.美国版权局强调,人类的提示词,在作品生成过程中不存在实质性贡献。
去年引起广泛热议的人工智能作品《太空歌剧院》,被美国版权局拒绝注册。美国版权局认为,基于现有材料并不能判断AI及艾伦在整个作品创作过程中的贡献占比,但无可争议的是,由AI占实质性贡献的部分不能获得版权的保护,应当予以剔除……但在具体工作中AI是参照提示进行自主性的创作,使得用户需要对结果进行优化和重整以获得自己满意的结果,这说明人类用户在过程中并不占主导性地位,此种提示在作品生成的过程中不存在实质性贡献[6]。
2.对AIGC相对开放的日本,认为“创造性贡献”的认定也难有标准。
日本文化厅也讨论了“设定参数是否应当被视为创造性贡献”的话题,在其流传甚广的一份PPT中,文化厅认为:鉴于人工智能技术的变化极为迅速,而且缺乏许多具体的实例,目前很难确定具体的方向,即有多少参与可以被认定为创造性贡献……在密切关注人工智能技术发展的同时,宜根据具体案例继续研究人工智能创作的可版权性与创造性贡献之间的关系[7]。

(日本文化厅网传关于《AI与著作权研讨会》的PPT截图)
说到这里,我又想起开篇我们提到的北互9月份的“典型案例”,那份经典判例里斩钉截铁的“计算机软件智能生成内容不能构成作品”的认定,恐怕才是当下更为慎重、恰当的观点。
不过话说回来,全网热烈讨论的“AI生成图片著作权侵权第一案”,判决书落款的时间是2023年11月27日,也就是笔者发文的当下,本案还在上诉期内。
本案最终如何定论,尚未可知也。
甚至就算本案定论了,AIGC的可版权性就定论了吗?
注释
[1]参见《北京互联网法院数据算法十大典型案件|砥砺五载·典型案例篇》,https://mp.weixin.qq.com/s/XRB3TqJs-VL67FjKkO-IMw[2]参见《谁拥有算力,谁垄断国内AI著作权的未来?》,作者李伯阳,https://mp.weixin.qq.com/s/gYMZ6_m_83QcKBicc_luxw[3]参见《AI生成图片著作权侵权第一案判决书》,https://mp.weixin.qq.com/s/Wu3-GuFvMJvJKJobqqq7vQ[4]《独一无二的伊万》,女作家凯瑟琳·阿普盖特(Katherine Applegate)根据真实故事创作,导演瑟雅·莎罗克,于2020年8月21日在流媒体上线,源自百度百科词条[5]《深入浅出讲解Stable Diffusion原理,新手也能看明白》,作者北方的郎,https://zhuanlan.zhihu.com/p/627133524?utm_id=0[6]《AIGC著作权问题综述与中美前沿案例解析》,作者刘名、方懿,https://mp.weixin.qq.com/s/VpcT5JPglXTQiI3NbvwAnQ[7]《日本AI与著作权研讨会》,日本文化厅,https://restofworld.org/2023/japans-new-ai-rules-favor-copycats-over-artists/
(本文仅代表作者观点,不代表知产力立场)
封面来源 | 知产力



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}